Setting up Samba as an Active Directory Domain Controller
Samba4 HOWTO
This document explains how to setup a simple Samba4 server. This is aimed at people who are already familiar with Samba3 and wish to participate in Samba4 development or test the alpha releases of Samba4. This is not aimed at general production use of Samba4, although some brave sites are running Samba4 in production based on these instructions.
Video demonstrations of this HOWTO
A set of demonstration videos is available that may provide a useful overview of this contents of this HOWTO
A note on alpha/beta versions
Samba4 is developing very rapidly. This HOWTO is frequently updated to reflect the latest changes in the Samba git repository. Please see the Samba4 Status Wiki for more specifics on project status.
Step 1: Download Samba4
If you have downloaded the Samba4 code via a tarball released from the samba.org website, Step 1 has already been completed for you. For testing with the version released in the tarball, you may continue on to Step 2.
Note that the references below to the top-level directory named "samba-master" will instead be based on the name of the tarball downloaded (e.g. "samba-4.0.0alpha13" for the tarball samba-4.0.0alpha13.tar.gz). Also note that in the "master" branch the samba4 code in our current git tree is now located in the top level directory.
Otherwise there are two methods for downloading the current samba version:
- via git
- via rsync
If you don't have rsync or git then install one of them, or stick to the latest tarball release. If you have a choice, we strongly recommend using the git method for downloading Samba, as it makes getting updates easier, and also allows you to integrate test patches from Samba developers more easily in case of problems.
git
$ git clone git://git.samba.org/samba.git samba-master; cd samba-master
or via http:
$ git clone http://gitweb.samba.org/samba.git samba-master; cd samba-master
This will create a directory called "samba-master" in the current directory.
If you want to update the tree to the latest version run:
$ git pull
rsync
$ rsync -avz samba.org::ftp/unpacked/samba_4_0_test/ samba-master
Note that the above rsync command will give you a checked out git repository, but it needs some changes so that you can update it using git:
$ cd samba-master/ $ rm .git/refs/tags/* $ rm -r .git/refs/remotes/ $ git config remote.origin.url git://git.samba.org/samba.git $ git config --add remote.origin.fetch +refs/tags/*:refs/tags/* (this line is optional) $ git fetch
Note you can ignore this error from git fetch: error: refs/heads/master does not point to a valid object!
You can update it to the latest version at some future date using:
$ git pull
If you get an error like this:
fatal: Unable to create '[...]/samba_master/.git/index.lock': File exists.
remove the lock file and try running "git pull" again.
Step 2: Compile Samba4
Required development libraries:
- Python development libraries (python-dev in Debian/Ubuntu) required to compile
Recommended optional development libraries:
- acl and xattr development libraries (libacl1-dev, libattr1-dev packages in Debian/Ubuntu)
- blkid development libraries (libblkid-dev package in Debian/Ubuntu)
- gnutls (libgnutls-dev package in Debian/Ubuntu)
- readline (libreadline-dev package in Debian/Ubuntu)
- openldap (libldap2-dev package in Debian/Ubuntu; openldap2-devel in openSUSE) is required to build the Samba3 components with LDAP support. Lacking this library the build will complete but attempts to provision (via upgrade) an Active Directory domain from an existing Samba3 LDAP backend will fail.
For Debian/Ubuntu:
$ apt-get install build-essential libacl1-dev libattr1-dev \ libblkid-dev libgnutls-dev libreadline-dev python-dev \ python-dnspython gdb pkg-config libpopt-dev libldap2-dev \ bind9utils dnsutils
For Fedora:
$ yum install libacl-devel libblkid-devel gnutls-devel \ readline-devel python-devel gdb pkgconfig
For Red Hat Enterprise Linux 6.x or CentOS 6.x:
$ yum install libacl-devel libblkid-devel gnutls-devel \ readline-devel python-devel gdb pkgconfig krb5-workstation $ yum install zlib-devel setroubleshoot-server \ setroubleshoot-plugins policycoreutils-python \ libsemanage-python setools-libs-python setools-libs \ popt-devel libpcap-devel sqlite-devel libidn-devel \ libxml2-devel libacl-devel libsepol-devel libattr-devel \ keyutils-libs-devel cyrus-sasl-devel
For openSUSE 11.4 or openSUSE 12.1:
$ zypper install libacl-devel python-selinux autoconf make \
python-devel gdb sqlite3-devel libgnutls-devel binutils \
policycoreutils-python setools-libs selinux-policy \
setools-libs popt-devel libpcap-devel keyutils-devel \
libidn-devel libxml2-devel libacl-devel libsepol-devel \
libattr-devel zlib-devel cyrus-sasl-devel gcc \
krb5-client openldap2-devel libopenssl-devel
For Gentoo:
$ USE="dlz python gssapi" emerge cyrus-sasl heimdal bind bind-tools gnutls dnspython gdb libidn subunit $ ACCEPT_KEYWORDS="~amd64" USE="python" emerge =sys-libs/tdb-1.2.10 =sys-libs/tevent-0.9.15 =sys-libs/ldb-1.1.6
Obviously that would be ~x86 instead of ~amd64 on a x86 arch, also don't forget to
$ eselect python set 1
where 1 is python 2.X (3.X is not yet supported) if you don't know which version you are using, eselect python list will give you a list of available ones.
To build, run this:
$ cd samba-master $ ./configure.developer $ make
The above command will setup Samba4 to install in /usr/local/samba. If you want Samba to install somewhere else then you should use the --prefix option to configure.developer.
The reason we recommend using configure.developer rather than configure for Samba4 alpha releases is that it will include extra debug information that will help us diagnose problems in case of failures. It will also allow you to run the various builtin automatic tests.
Step 3: Install Samba4
Run this as a user who have permission to write to the install directory (which defaults to /usr/local/samba). Use --prefix option to configure.developer above to change this.
$ make install
For the rest of this HOWTO we will assume that you have installed Samba4 in the default location, which is /usr/local/samba.
Step 4: Provision Samba4
The "provision" step sets up a basic user database, and is used when you are setting up your Samba4 server in its own domain. If you instead want to setup your Samba4 server as an additional domain controller in an existing domain, then please see the separate page on Samba4 joining a domain. If you want to migrate an existing Samba3 domain to Samba4, see the Migrating an Existing Samba3 Domain to Samba4 section on this page.
In the following examples we will assume your DNS domain name is 'samdom.example.com' and your short (also known as NT4) domain name is 'samdom'. We will assume that your Samba servers hostname is samba.
It must be run as a user with permission to write to the install directory (which means you may need to run this command with sudo)
# /usr/local/samba/sbin/provision \ --realm=samdom.example.com --domain=SAMDOM \ --adminpass=SOMEPASSWORD --server-role=dc
If you get an error like this:
tdb_open_ex: could not open file /usr/local/samba/private/sam.ldb.d/DC=SAMDOM,DC=EXAMPLE,DC=COM. ldb: Permission denied
then you need to rerun with sudo
Troubleshooting note: you may need to rm the smb.conf file if you failed to pass valid names and provision previously failed
There are many other options you can pass to the 'provision' command, run it with the --help option to see a list of them.
- Note: when using debian SID samba4 package, provision script and samba4 installation will abort if hostname -d is returning an empty string (domainname not found). Indeed debian4.config script get REALM as follow REALM=`hostname -d | tr 'a-z' 'A-Z'`. So check /etc/resolv.conf contains:
domain samdom.example.com
Step 5: Starting Samba4
If you are planning to run Samba4 as a production server, then just run the "samba" binary as root
# samba
That will run Samba4 in 'standard' mode, which is suitable for production use. Samba4 alpha13 doesn't yet have init scripts included for each platform, but making one for your platform should not be difficult. There are some example scripts (for RedHat/Fedora and Debian/Ubuntu) on the Samba4/InitScript page.
If you are running Samba4 as a developer you may find the following more useful:
# samba -i -M single
that means start "samba" with messages in stdout, and running a single process. That mode of operation makes debugging "samba" with gdb particularly easy. If you want to launch it under gdb, then the following example could be useful:
$ sudo gdb --args bin/samba -i -M single
Note that if you are running any Samba3 smbd or nmbd processes they need to be stopped before starting "samba" from Samba 4.
Make sure you put the bin and sbin directories from your new install in your $PATH or you may end up running the wrong version. You can see what version you have by running "samba -V".
Note: in older developer versions of samba4 "samba" was still called "smbd".
Step 6: Testing Samba4
First check you have the right version of smbclient in your $PATH
$ smbclient --version
This should show you a version starting with "Version 4.0.XXXXX".
Now try this command:
$ smbclient -L localhost -U%
That should show you a list of shares available on your server. For example:
Sharename Type Comment
--------- ---- -------
netlogon Disk
sysvol Disk
IPC$ IPC IPC Service (Samba 4.0.0alpha12-GIT-5e755e9)
ADMIN$ Disk DISK Service (Samba 4.0.0alpha12-GIT-5e755e9)
The 'netlogon' and 'sysvol' shares are basic shares needed for Active Directory server operation.
If this is not (or not anymore) working, and you have a message like that:
Failed to connect to ncacn_np:localhost - NT_STATUS_NO_MEMORY REWRITE: list servers not implemented
Then stop samba, and check for the presence of /usr/local/samba/var/run/smbd-fileserver.conf.pid, if present remove it
To test that authentication is working, you should try to connect to the netlogon share using the administrator password you set earlier.
$ smbclient //localhost/netlogon -Uadministrator%PASSWORD
You should get a "smb>" prompt, and access to your netlogon directory.
The provisioning will create a very simple smb.conf with no shares by default. For the server to be useful you will need to update it to have at least one share. For example:
[test]
path = /data/test
read only = no
Note that in current alpha versions of Samba4 you need to restart Samba to make new shares visible. This will be fixed in a future release.
Step 8 Configure DNS
A working DNS setup is essential to the correct operation of Samba4. Without the right DNS entries, kerberos won't work, which in turn means that many of the basic features of Samba4 won't work.
It is worth spending some extra time to ensure your DNS setup is just right, as debugging problems caused by mis-configured DNS can take a lot of time later on.
The simplest way to get a working DNS setup for Samba4 is to start with the DNS configuration file that are created by the 'provision' step above. If you look in /usr/local/samba/private directory, you'll find a file called 'named.conf'.
Assuming your have a bind9.8.x or newer DNS server installed, you can activate the configuration that the provision has created by adding a line like this to /etc/bind/named.conf.local:
include "/usr/local/samba/private/named.conf";
After adding that line you should restart your bind server and check in the system logs for any problems.
Note that the /usr/local/samba/private/named.conf requires at least bind 9.8.x to function and you may need to edit the /usr/local/samba/private/named.conf file to use the bind 9.9.x module (need to verify this).
One common problem is that many modern Linux distributions activate 'Apparmor' or 'SELinux' by default, and these may be configured to deny access to bind for your the named.conf and zone files created in the provision. If your bind logs show that bind is getting a access denied error accessing these files then please see your local system documentation for how to enable access to these files in bind (hint: for Apparmor systems such as Ubuntu, the command aa-logprof may be useful).
Now you need to test that DNS is working correctly. Check that your /etc/resolv.conf is pointing correctly at your local DNS server, then run the following commands:
$ host -t SRV _ldap._tcp.samdom.example.com. _ldap._tcp.samdom.example.com has SRV record 0 100 389 samba.samdom.example.com.
$ host -t SRV _kerberos._udp.samdom.example.com. _kerberos._udp.samdom.example.com has SRV record 0 100 88 samba.samdom.example.com.
$ host -t A samba.samdom.example.com. samba.samdom.example.com has address 10.0.0.1
Check that you get answers similar to the ones above (adjusted for your DNS domain name and hostname). If you get any errors then carefully check your system logs to find and fix the problem.
- Note: One of the problems I've had on Debian system is that the zone autogeneration always detects, and uses, 127.0.1.1 as the domain controller's IP address. That works fine until you 1) Don't have a 127.0.1.1 interface on the machine or 2) Go to join your first client to the domain. In /usr/local/samba/private/named.conf you might need to change 127.0.1.1 to reflect the actual IP address of the server you're setting up.
- Note: On debian SID (bind9 package), /etc/bind/named.conf.options is missing and prevent named daemon to be started and installation to be completed (create an empty file or comment out corresponding line in /etc/bind/named.conf see syslog messages)
Step 9: Testing kerberos
Once DNS is working, you should test that kerberos server builtin to Samba4 is working correctly.
Before testing, first configure the krb.conf file (/etc/krb.conf on RHEL like systems), replace the existing one with the sample from /usr/local/samba/share/setup/krb5.conf. Edit the file and replace ${REALM} with you domain name.
The easiest test is to use the kinit command like this:
$ kinit administrator@SAMDOM.EXAMPLE.COM Password:
Note:
- You have to give your 'domain realm SAMDOM.EXAMPLE.COM' in uppercase letters to kinit.
The kinit should completely successfully. After it completes you can examine the received ticket like this:
$ klist -e
Ticket cache: FILE:/tmp/krb5cc_1000
Default principal: administrator@SAMDOM.EXAMPLE.COM
Valid starting Expires Service principal
02/10/10 19:39:48 02/11/10 19:39:46 krbtgt/SAMDOM.EXAMPLE.COM@SAMDOM.EXAMPLE.COM
Etype (skey, tkt): ArcFour with HMAC/md5, ArcFour with HMAC/md5
If you find you don't have kinit or klist, you may need to install them. On debian based systems (such as Ubuntu) the packages are called krb5-config and krb5-user.
You can also test kerberos form a remote client, just make sure you have configure the krb5.conf and the resolve.conf to point to the domain controller IP address.
Note:
- If you are using a client behind NAT then you have to add the following to the krb5.conf on the domain controller server:
[kdc]
check-ticket-addresses = false
Step 10 Configure kerberos DNS dynamic updates (optional)
To setup dynamic DNS updates you need to have a recent version of bind9 installed. It is highly recommended that you install at least version 9.8.0 as that version includes a set of patches from the Samba Team to make dynamic DNS updates much more robust and easier to configure. In the instructions below we give instructions for both bind 9.7.2 and 9.8.0, but please use 9.8.0 or later if at all possible.
For Debian Lenny:
If you also want to use Dynamically Loadable Zones (DLZ) then you should add the corresponding option (dlopen) depending on your version of bind. If you are about to compile a downloaded tarball you might need these libraries: libkrb5-dev and libssl-dev
$ apt-get install libkrb5-dev libssl-dev $ tar -zxvf bind9.x.x.tar.gz $ cd bind9.x.x
Bind9.8.0
$ ./configure --with-gssapi=/usr/include/gssapi --with-dlz-dlopen=yes
Bind9.8.1
$ ./configure --with-gssapi=/usr/include/gssapi --with-dlopen=yes
$ make $ make install
You can tell what version of bind9 you have using the command "/usr/sbin/named -V". If your OS does not have bind9 9.8.0 or later, then please consider getting it from a package provided by a 3rd party (for example, on Ubuntu there is a ppa available with the newer versions of bind9).
Instructions for bind9 9.8.0 or later
When using bind9 9.8.0 or later you should add a line like the following to the options section of your bind9 config:
options {
[...]
tkey-gssapi-keytab "/usr/local/samba/private/dns.keytab";
[...]
};
On some systems (such as Ubuntu) this is located in /etc/bind/named.conf.options. Otherwise look for the "options {" part of your bind9 configuration.
You also need an include line pointing at the named.conf in the private directory of your Samba install (this file is created by the provision command):
include "/usr/local/samba/private/named.conf";
On Debian based systems (such as Ubuntu) this include line is normally put in /etc/bind/named.conf.local. On RedHat based systems it goes in /etc/named.conf.
Instructions for bind9 9.7.x
If you have bind9 9.7.x (specifically 9.7.2 or later), then first determine if you can at all possibly run bind 9.8. You will have far fewer problems. Otherwise, follow these instructions.
The Samba provision will have created a custom named.conf.update configuration file in the private directory of your Samba install. You need to include in your master named.conf to allow Samba/Kerberos DNS updates to automatically take place. Be advised that if you include this file in Bind versions that don't support it, Bind will fail to start.
You additionally need to set two environment variables for bind9 when using bind9 version 9.7.x:
KEYTAB_FILE="/usr/local/samba/private/dns.keytab" KRB5_KTNAME="/usr/local/samba/private/dns.keytab" export KEYTAB_FILE export KRB5_KTNAME
These should be put in your settings file for bind9. On Debian based systems (including Ubuntu) this is in /etc/default/bind9. On RedHat and SUSE derived systems it is in /etc/sysconfig/named. Strictly speaking you only either need KEYTAB_FILE or KRB5_KTNAME, but which you need depends on your distro, so it's easier to just set both.
The dns.keytab must be readable by the bind server user this could be accomplished by executing:
$ chown named.named /usr/local/samba/private/dns.keytab
(the provision should have setup these permissions for you automatically).
Then in your /etc/bind/named.conf.options you need this:
tkey-gssapi-credential "DNS/server.samdom.example.com"; tkey-domain "SAMDOM.EXAMPLE.COM";
The last part of the credential in the first line must match the dns name of the server you have set up.
Debugging dynamic DNS updates
The way the automatic DNS update in Samba works is that the provision will create a file /usr/local/samba/private/dns_update_list, which contains a list of DNS entries that Samba will try to dynamically update at startup and every 10 minutes thereafter using samba_dnsupdate utility. Updates will only happen if the DNS entries do not already exist. Remember that you need nsupdate utility from bind distribution for all these to work (dnsutils package in Debian/Ubuntu).
If you want to debug this process, then please run this as root:
/usr/local/samba/sbin/samba_dnsupdate --verbose
that will give you more information on the updates that Samba is doing at runtime, and show you any errors that are generated.
Interaction with apparmor or SELinux
Now you have to ensure that bind can read the dns.keytab file, the named.conf file and the zone file. It also needs to be able to write the zone file. The Samba provision tries to setup the permissions correctly for these files, but you may find you need to make changes in your Apparmor or SELinux configuration if you are running either of those. If you are using Apparmor then the aa-logprof command may help you add any missing permissions you need to add after you start Samba and bind9 for the first time after configuring them.
You should also carefully check the permissions on the private/dns directory to ensure it is writeable by bind.
Step 11 Configure NTP (optional)
RedHat 6.x: Redhat does not provide a recent NTP version to support signed ntp so a newer version is required.
1. Download NTP =>4.2.6 release from ntp.org ( verify md5 sum )
2. Download the Redhat 6.1 ntp source rpm file from RedHat and install.
3. Edit the ntp.spec and remove all lines regarding patches and correct the version number.
4. Here is a partial diff showing required edits then run $ rpmbuild -ba ntp.spec
218c115
< --enable-linuxcaps
---
> --enable-linuxcaps --enable-ntp-signd
327a225
> %{_sbindir}/sntp
345,346c243,244
< %{_mandir}/man8/ntptime.8*
< %{_mandir}/man8/tickadj.8*
---
> %{_mandir}/man8/ntpdtime.8*
> #%{_mandir}/man8/tickadj.8*
352c250
< %{_mandir}/man8/ntp-wait.8*
---
> #%{_mandir}/man8/ntp-wait.8*
For Debian/Ubuntu:
Recent versions of Debian/Ubuntu already contain a version of ntp with support for signing. For older versions (Debian Squeeze, Ubuntu < 11.04), get a recent version of ntp:
$ tar -zxvf ntp-4.x.x.tar.gz $ cd ntp-4.x.x $ ./configure --enable-ntp-signd $ make $ make install
5. TODO ( add example ntp.conf changes )
# A simple ntp.conf tested in Debian Lenny # Using the hardware clock server 127.127.1.1 fudge 127.127.1.1 stratum 12 ntpsigndsocket /usr/local/samba/var/run/ntp_signd/ restrict default mssntp [...]
NOTES on permissions, SELinux labeling and policy
RedHat 6.X:
There is still more work TODO in regards of creating a Samba4 specific SELinux policy but for now you should be able to have everything working *without* disabling SELinux.
Based on the provision example above set this ENV for commands below :
MYREALM="samdom.example.com"
Change permissions:
chown named:named /usr/local/samba/private/dns chgrp named /usr/local/samba/private/dns.keytab chmod g+r /usr/local/samba/private/dns.keytab chmod 775 /usr/local/samba/private/dns
Label files ( ensure $MYREALM is correct ):
chcon -t named_conf_t /usr/local/samba/private/dns.keytab
chcon -t named_conf_t /usr/local/samba/private/named.conf.update
chcon -t named_var_run_t /usr/local/samba/private/dns
chcon -t named_var_run_t /usr/local/samba/private/dns/${MYREALM}.zone
Needed for persistence of labels ( ensure $MYREALM is correct ):
semanage fcontext -a -t named_conf_t /usr/local/samba/private/dns.keytab
semanage fcontext -a -t named_conf_t /usr/local/samba/private/named.conf
semanage fcontext -a -t named_conf_t /usr/local/samba/private/named.conf.update
semanage fcontext -a -t named_var_run_t /usr/local/samba/private/dns
semanage fcontext -a -t named_var_run_t /usr/local/samba/private/dns/${MYREALM}.zone
semanage fcontext -a -t named_var_run_t /usr/local/samba/private/dns/${MYREALM}.zone.jnl
semanage fcontext -a -t ntpd_t /usr/local/samba/var/run/ntp_signd
NOTE: Multiple attempts to set the context for ntp failed so (below) policy was needed for windows clients time sync after joining the DOMAIN.
$ chcon -u system_u -t ntpd_t /usr/local/samba/var/run/ntp_signd $ chcon -u system_u -t ntpd_t /usr/local/samba/var/run/ $ chcon -t ntpd_t /usr/local/samba/var/run/ntp_signd/socket
samba4.te policy:
module samba4 1.0;
require {
type ntpd_t;
type usr_t;
type initrc_t;
class sock_file write;
class unix_stream_socket connectto;
}
#============= ntpd_t ==============
allow ntpd_t usr_t:sock_file write;
#============= ntpd_t ==============
allow ntpd_t initrc_t:unix_stream_socket connectto;
Check and load policy:
$ checkmodule -M -m -o samba4.mod samba4.te $ semodule_package -o samba4.pp -m samba4.mod $ semodule -i samba4.pp
NOTE about filesystem support
To use the advanced features of Samba4 you need a filesystem that supports both the "user" and "system" xattr namespaces.
If you run Linux with a 2.6 kernel and ext3 this means you need to include the option "user_xattr" in your /etc/fstab. For example:
/dev/hda3 /home ext3 user_xattr 1 1
You also need to compile your kernel with the XATTR and SECURITY options for your filesystem. For ext3 that means you need:
CONFIG_EXT3_FS_XATTR=y CONFIG_EXT3_FS_SECURITY=y
If you are running a Linux 2.6 kernel with CONFIG_IKCONFIG_PROC defined you can check this with the following command:
$ zgrep CONFIG_EXT3_FS /proc/config.gz
If you don't have a filesystem with xattr support, then you can simulate it by using the option:
posix:eadb = /usr/local/samba/eadb.tdb
that will place all extra file attributes (NT ACLs, DOS EAs, streams etc), in that tdb. It is not efficient, and doesn't scale well, but at least it gives you a choice when you don't have a modern filesystem.
Testing your filesystem
To test your filesystem support, install the 'attr' package and run the following 4 commands as root:
# touch test.txt # setfattr -n user.test -v test test.txt # setfattr -n security.test -v test2 test.txt # getfattr -d test.txt # getfattr -n security.test -d test.txt
You should see output like this:
# file: test.txt user.test="test"
# file: test.txt security.test="test2"
If you get any "Operation not supported" errors then it means your kernel is not configured correctly, or your filesystem is not mounted with the right options.
If you get any "Operation not permitted" errors then it probably means you didn't try the test as root.
If you are using the posix:eadb option then you don't need to test your filesystem in this manner.
Profiling with google-perftools
LDFLAGS="-ltcmalloc -lprofiler" ./configure --enable-developer .....
This also works for CFLAGS
Configure a Windows Client to join a Samba 4 Active Directory
Active Directory is a powerful administration service which enables an administrator to centrally manage a network of Windows 2000, Windows XP Pro, Windows 2003, and Windows Vista Business Edition effectively. To test the real Samba 4 capability, we use Windows XP Pro as testing environment (Windows XP Home doesn't include Active Directory functionality and won't work).
To allow Samba 4 Active Directory or Microsoft Active Directory to manage a computer, we need to join the computer into the active directory. It involves:
- Configuring DNS Setting
- Configuring date/time and time zone
- Joining the domain
Step 1: Configure DNS Setting for Windows
Before we configure the DNS setting, verify that you are able to ping the Server's IP Address. If you are not able to ping the server, double check your IP address, firewall, routing, etc.
Once you have verified network connectivity between the Samba server and client,
- Right Click My Network Places -> Properties
- Double click local area network->Properties
- Double click tcp/ip
- Use static dns server, add the Samba 4 server's ip address inside the primary dns server column.
- Press ok, ok, ok again until finished.
- Open a command prompt, type 'ping servername.your.realm' (change to suit your custom realm per your provision)

If you get replies, then it means your Windows XP settings are correct (for DNS) and Samba4 Server's DNS services is working as well.
Step 2: Configure date/time and time zone
Active Directory uses Kerberos as the backend for authentication. Kerberos requires that the system clock on the client and server be synchronized to within a few seconds of each other. If they are not synchronized, authentication will fail for apparently no reason.
- Change the timezone in Windows XP Pro so that server and client using same time zone. In my computer, I use Asia/Kuala_Lumpur (I come from Malaysia).
- Change the date/time so the client have same HH:MM with the server.


Step 3: Joining the Windows client into domain
Now your Windows is ready to join the Active Directory (AD) domain,
As administrator:-
- Right Click my Computer-> Properties
- Choose Computer Name, click change..
- Click option 'Domain', insert YOUR.REALM (if you failed, try YOURDOM)(
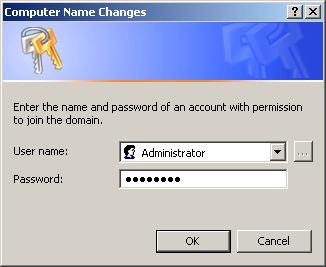
- When it request username/password, type administrator as username, SOMEPASSWORD as password (per your earlier provision).
- It will tell you the Windows XP has successfully join into Active Directory Domain, and you need to restart.
- After restart, you should get the normal domain logon dialog
- Choose domain YOURDOM, insert username administrator as username, SOMEPASSWORD as password (again, per your earlier provision)
- If you login successfully, then you able to enjoy samba 4 active directory services at next section.

Viewing Samba 4 Active Directory object from Windows
We need install windows 2003 adminpak into windows XP in order to use GUI tools to manage the domain. Before begin, make sure the domain administrator have administrative right to control your computer.(To give any user administrative right, in Windows XP Pro, right click my computer, press manage-> choose groups-> double click administrators and add members from domain into the member list. During you add member from active directory as member, it will prompt you to enter active directory username/password).
Step 1: Installing Windows Remote Administration Tools onto Windows
Windows7
- Download the Windows Remote Administration Tools from
- and follow the "Install RSAT" instructions
Vista
Download the Windows Remote Administration Tools from
and follow the "Install RSAT" instruction described at
Windows XP Pro
- In Windows XP, download adminpak and supporttools from
- http://www.microsoft.com/downloads/en/details.aspx?FamilyID=86b71a4f-4122-44af-be79-3f101e533d95
- http://download.microsoft.com/download/3/e/4/3e438f5e-24ef-4637-abd1-981341d349c7/WindowsServer2003-KB892777-SupportTools-x86-ENU.exe
- If you installed an older version of the adminpak, you'll notice the dial-in tab is missing from property pages. Just follow the link above to get SP2 which does not have this issue.
- Run through the installation.
- Press start->run, type 'dsa.msc', if a window 'active directory users and computers' prompt up, it mean you had install adminpak it successfully. You can also find this at Start>Programs>Administrative Tools, which should have a lot more items now.
- Go to c:\Program Files\Support Tools to check whether the support tools were installed correctly; if yes, then your XP workstation is ready to manage the Samba 4 Active Directory.
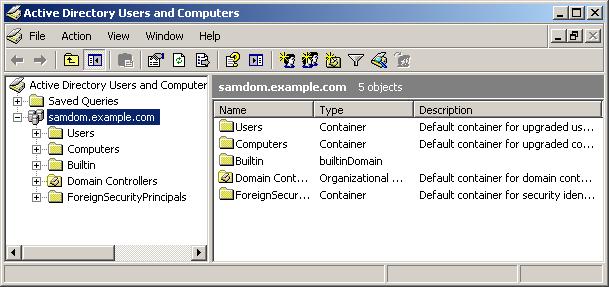
Step 2: Viewing samba 4 active directory content
- Login as domain 'testing1.org' administrator, press start->run.
- type dsa.msc
- Expand the testing1.org tree to see existing object in domain.


Managing Samba 4 Active Directory From Windows XP Pro
One of Samba4's goals is to integrate with (and replace) Active Directory as a system. At this point, if everything has worked correctly you should have an "Administrative Tools" menu under Programs. If, under Administrative Tools you have "Active Directory Users and Computers", that is a very good sign. Most times, if there is a configuration or bug in Samba4, the AD Users & Computers (among other interfaces) won't show up as an option. You can run it by hand (Start->Run->dsa.msc) but it's unlikely to work correctly.
Step 1: Adding user into Samba 4 Active Directory
Unlike Samba3, Samba4 does not require a local unix user for each Samba user that is created.
To create a Samba user, use the command
samba-tool user add USERNAME
To inspect the allocated user ID and SID, use wbinfo
$ bin/wbinfo --name-to-sid USERNAME S-1-5-21-4036476082-4153129556-3089177936-1005 SID_USER (1) $ bin/wbinfo --sid-to-uid S-1-5-21-4036476082-4153129556-3089177936-1005 3000011
If you want to change this mapping, then use ldbedit on the idmap.idb, like this:
$ bin/ldbedit -e emacs -H /usr/local/samba/private/idmap.ldb objectsid=S-1-5-21-4036476082-4153129556-3089177936-1005
You will find records that look like this:
# record 1 dn: CN=S-1-5-21-4036476082-4153129556-3089177936-1005 cn: S-1-5-21-4036476082-4153129556-3089177936-1005 objectClass: sidMap objectSid: S-1-5-21-4036476082-4153129556-3089177936-1005 type: ID_TYPE_BOTH xidNumber: 3000011 distinguishedName: CN=S-1-5-21-4036476082-4153129556-3089177936-1005
If you change the xidNumber attribute and save your editor then exit, then Samba will update the mapping to between the SID and the user ID. Updating group mappings works in the same way.
You can also manage users using the normal Windows AD user management tools.
Setting Up Roaming Profiles (Windows 7)
1. You will need to create a share for the profiles, typically named profiles. Edit the /usr/local/samba/etc/smb.conf to include:
[profiles]
path = /usr/local/samba/var/profiles
read only = no
2. Create the directory above using:
$ sudo mkdir /usr/local/samba/var/profiles
3. On windows start the Active Directory Users and Computers, select all the users, right click and hit properties
4. Under the profile tab, in the Profile path type the path to your share along with %USERNAME% as follows:
\\sambaserver.samdom.example.com\profiles\%USERNAME%
5. click OK, logout and login as one of those users. When you logout again, you should see that the profile has been synced onto the samba server.
Adding organization unit (OU) into samba 4 domain
Organizational Unit (OU), is a powerful feature in active directory. This is a type of container which allows you to drag & drop users and/or computers into it.
We can link several kind of group policy to an OU, and the settings will deploy to all users/computers under the OU. With a single domain we can have as many OU and sub OU as you like. So the result is that it can greatly reduce administrative overhead because you are able to manage everything via an OU. The implementation of group policy will be discussed in the next chapter.
Before we create an OU, we must know what an OU looks like. By default we can see a sample OU 'Domain Controllers', which uses a different icon in the Windows management tools to the 'users' and 'computers' container. We can deploy group policy to users or computers container.
- To create an OU, as the domain administrator, use start -> run -> dsa.msc
- right click on your domain.
- choose new -> organizational unit
- type OU Demo'
- Then you will see an new OU appear, with the name 'OU Demo'.
- You can drag your user 'demo' into the new OU (Don't move other users! Unless you want to get stuck!)
- Right Click the 'OU Demo', you can create a sub OU with New->Organizational.
Normally we create OU based the departmental setup of your organization. Be careful not to confuse groups and OUs, groups are used to control permissions, OU are used for deployment settings to all users/computers within the OU.
Implementing Group Policies (GPO) in a Samba4 domain
Samba4 Active Directory has support for group policies, and can create the group policy on the fly. The basic idea of group policies is:-
- Group Policies have 2 kind of settings, computers and users.
- Computer settings apply to computers, user settings apply to users
- We link the group policy to a particular OU, and the group policy will effect all computers/users under the OU.
- To add a group policy, right click 'OU Demo' OU->properties
- Choose group policy
- Press new, name as 'GP Demo'
- Press edit to edit the policy.
- Here will demonstrate how to block user from access the control panel. Open the tree 'User Configuration'->'Administrative Templates'->'control panel'.
- Double click on 'Prohibit access to the Control Panel'
- Press enabled and then press OK. Now the all users under 'OU Demo' won't able to access to the control panel.
- Make sure user demo is inside the 'OU Demo' (You can drag and drop it).
- Logout and login as user 'demo'
- You'll find user demo is not able to access control panel
- Note
- that user configuration will take effect once you logout and login.
- Computer
- configuration will take effect when you restart the computer
To learn more about managing and implementing organizational units, group policy, and active directory, try a web search for Google in Windows 2003 Active Directory implementation.
Installing the Group Policy Management Console
You may also find the Group Policy Management console useful. You can download it from:
http://www.microsoft.com/downloads/details.aspx?FamilyId=0A6D4C24-8CBD-4B35-9272-DD3CBFC81887&displaylang=en
This is primarily useful for when you have larger installs and are managing many machines. You may need to download the .NET framework first.
Joining a Windows domain controller as an additional DC in a domain
Once you have a Samba domain controller setup, you can choose to join additional domain controllers to the domain, whether they be additional Samba domain controllers, or additional Windows domain controllers.
If you wish to join an additional Samba domain controller to a domain, then please see the Joining a domain as a DC page. The instructions on that page are the same for joining Samba to a Windows domain as they are for joining Samba to an existing Samba domain.
If you wish to join a new Windows domain controller to a Samba domain, then you should use the 'dcpromo' tool on the Windows machine. Please see the normal instructions for installing dcpromo on Windows, with the exception that you should not tick the 'DNS server' option box when it is offered. Right now you should either use Windows for DNS, or use Samba and bind9 for DNS. Mixing the two can work, but it is an advanced topic that is beyond the scope of this howto.
Migrating an Existing Samba3 Domain to Samba4
It is very likely that you already have a running Samba3 domain on your network. The question is, how do you migrate that domain and all of its users and machines over to a new Samba4 based domain, without needing to move every user profile and machine to the new domain? The answer is the samba-tool domain classicupgrade function.
Report your success/failure!
Samba4 as a replicating domain controller is still developing rapidly, and we like to hear from users about their successes and failures. While Samba4 is still in alpha release we would encourage you to report both your successes and failures to the samba-technical mailing list on http://lists.samba.org
Please be aware that Samba4 is not complete, so you should deploy it carefully until it is ready for a non-alpha release.